AB实验中的难题
概览
| 问题类型 | 挑战 | 问题描述 | 解决方法 | 例子 |
|---|---|---|---|---|
| 灵敏度与统计功效类的问题 | Small Treatment Effects | 收益小但样本量又不够怎么办? | Variance Reduction / CUPED | 深度转化广告主价值进行指标capping;计刘侧广告主侧实验使用CUPED缩减方差 |
| Triggered Analysis | 只有一部分局部显著收益如何大盘收益? | 通过ATT和渗透率来反向预估ATE | 在实验场景下结合IV,PSM综合度量因果效应 | |
| Heterogeneous Treatment Effects | 如何识别不同个体面对相同的干预下的会不同差异(异质性)? | 线性模型/KNN/因果森林/Double Machine Learning | 用户研究方向的一些实验拆解(如端变量策略关注对load对不同用户活跃的影响,识别用户对于广告的敏感程度等) | |
| 实验设计与决策机制类问题 | Long-Term Effects | 如何在短期的实验里测出指标长期的变化避免决策短视? | 短期实验结果预测长期实验结果 | 中高广告侧堂试通过估计学习效应和中间指标推进预试实验长期LTV表规,预测依效结果强依赖于学习效应的趋势 |
| Optional Stopping | 如何避免挥择"优汇"汇?查量立实验NG吗? | 序贯检测(Sequential testing) | 暂无实际应用,采用矢方法绘制p-value曲线替代 | |
| Interference | 分单单低互干扰怎么办? | 隔离社区实验法/时间轮转法/TSR法 | 预算分桶 |
测算类问题:灵敏度和统计功效提升
灵敏度提升
在AB实验的假设检验过程中一直存在的一个不可能三角,即“收益小,方差大,样本量少”;具体实操中,如商业化的场景下,该挑战比比皆是,比如深度转化产品的转化稀疏导致广告主价值方差大,单一策略对其的影响通常是在「万分位」上的,往往需要很长的观测周期,积累大量样本,才能取得置信的结果,大部份流量实验是以周为单位开设的,流量有限;即收益小且样本量又不够在日常迭代必须要面对的一个问题,仅仅延长实验时间以缓解流量的枯竭会影响实验迭代效率
如何提高指标灵敏度呢?常见方法有
- 提高样本量
- 例如,interleaving实验机制代替传统AB实验
- 提高样本质量
- trimming (去掉异常值/outliers)或其他统计变换:对一些表现最极端异常的观测值,认为是异常值并予以剔除
- 去掉个别高方差/异常样本
- Triggered Analysis (下文详述)
- 修改指标定义
- disceretization: 通过卡阈值的方式将连续性指标转化成比率性指标(binarizing count metrics)如将曝光原始数据转化成【曝光大于X的内容占比】,将人均活跃天数转化成【是否活跃5天等】;–> 这类指标的重要挑选原则即为保证方向性(directionality),原指标在实验中表现为正向,binarizing后也应该为正向
- 拟合新指标:机器学习的方法,在保证同向性的情况下,将原本的指标当作,通过机器学习的方法找到可解释性最强的,拟合一个新的指标从而降低指标的方差(Yandex和FB使用了该方法)
- 方差缩减
- capping:对一些虽然比较大的数值(符合业务逻辑)直接进行替换,如直播打赏超过500的都记做500从而降低该指标的方差
- 依赖假设策略只对没有被cap的值影响/对是否cap值影响一致
- 阈值较难确定/可能实验间不稳定
- 利用实验前数据缩减方差
- CUPED
- 论文:Deng etl. Improving the Sensitivity of Online Controlled Experiments by Utilizing Pre-Experiment Data
- 要求是实验前后的指标相关性较强(例如用户时长等)
- Post Stratification/variance-weighted estimator:使用个体层面方差估计的加权估计量能够降低处理效应估计的方差,且证明了样本总体方差的变异系数是确定可能方差缩减规模的充分统计量
- optimal sampling methods:利用改进抽样方法等提升灵敏度,举要具体结合场景分析效
- Karmarkar-Karp heristic
- Stratified sampling
- 层间方差远小于层内方差时达到总体方差缩减
- Post-stratification
- CUPED
- capping:对一些虽然比较大的数值(符合业务逻辑)直接进行替换,如直播打赏超过500的都记做500从而降低该指标的方差
- 非参数检验
- 例如
CUPED 使用的例子
假设随机变量代表进组用户在实验开启后的app使用时长(Stay_Duration),是我们关注的指标。代表进组用户的平均使用时长,假设我们有另一个随机变量,在CUPED中,一般取用户在实验开启前的同一指标,i.e.用户在实验开启前的app使用时长。定义一个新的统计量:
,(公式1)
其中,是变量的理论期望值,是个参数(是个数)。
此时:
也就是说,与的无偏估计。
与此同时:
,(公式2)
注意,新指标的方差是关于的一个一元二次函数并且开口向上的抛物线,当
时,取得最小值
Triggered Analysis
- 某些策略需要用户采取主动行为来“采纳”,例如需报名才能得到激励奖励,需要某种行为才能被干预到,存在漏斗的场景。这时平均处理效应会受到“渗透率/触发率” 的影响
- Triggered Analysis通过仅分析实际被实验干预到的用户(如进入支付页的用户)来提高实验灵敏度,虽然样本量减少但可避免处理效应被未触发用户稀释。即如果真正triggered用户占比很小,那么平均处理效应将会大大低估,这时仅观察triggered用户是缓解低估的好办法。这里主要挑战有两点:
- 将triggered用户上的结果推广至全集上;
- 降低ATE的方差来抵消triggered用户样本量小对灵敏度的削弱
. Diluted treatment effect estimation for trigger analysis in online controlled experiments. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining")
- 方法一:user-triggered analysis(常用)
- 样本选择:观测triggered用户从第一次被trigger后,在实验周期内所有事件;
- 优点:对处理效应没有假设;可以看user - level的指标;
- 被证实可以提升统计功效、降低方差。
- 方法二:session-trigger analysis
- 样本选择:观测triggered用户被触发的session
- 优缺点:降低方差的能力比user - triggered更强,但强假设:处理效应只发生在被触发的session。
- 估计:diluted formulas
- 示例
-

- ITT (Intention-to-treat),估计的是我们意图想要让策略生效(但其中有一部分有主见的用户)的人群,也就是实验组A1+A2整体,的策略人均效果
- ATT (Average treatment effect on the treated),估计的是策略实际生效人群的策略人均效果
-
- 找出可比人群A1和B1,利用ATT反推ATE/ITT
- 处理效应绝对值:
- 比例型指标:,其中是平均触发率(分母的函数)
- 可以和CUPED等方法集合缩减方差
- 示例
- 常见问题
-
借助IV评估ATT的思路可否应用到有always taker的情况?
-
估计量并不完全一致。IV估计的是LATE,即compliers的treatment effect。在没有always taker的情况下,对T = 1的估计就等于是对compliers的估计,即LATE=ATT。然而在有always taker的情况下,可以理解为IV估计的compliers是ATT中一部分treated units,不代表整个采纳的ATT。因此采用2sls和采用PSM估计的估计量并不相同。
T = 0 T = 1 Z = 0 Never taker + compiler Always taker Z = 1 Never taker Always taker + compiler
-
-
对ATT的估计结果可以外推到全体人群吗?即看到功能对compliers有显著效果,可以将功能前置应用到所有人,并认为其效果即为ATT估计的效果吗?
- 不可以。compliers是用户自选择的结果,其分布与大盘不同,在compliers上估计的ATT并不代表大盘整体的效果,若在compliers上看到显著性结论并考虑将功能前置(比如从手动点击改为pop - up弹窗)面向全量人群,则需基于新的产品逻辑重新做实验测算。
-
如何找出和A1可比的样本B1?
- 利用工具变量(IV)
- AB实验分流信息本身是完美的工具变量;我们只需要知道实验组中complier比例即可估计全部因果效应
- 假设
- Z->T->Y: Z对Y的影响完全经由T产生;Z和Y不存在后门路径;单调性假设(T(Z=1) > T(Z=0))即实验组对照组不存在defier和always-taker;仅有complier和never-taker
- 问题
- IV本身无法提升灵敏度或显著性: 在策略存在漏斗的场景下,如果AB实验得到的ITT(reduced-form estimation)不显著,那么工具变量得到的LATE大概率不会显著。
- 工具变量估计的显著性基本上跟reduced-form estimation一致。所以LATE并不是一个提升策略效果估计显著性的手段。
- 使用LATE的motivation一般是当策略存在漏斗时,我们更关心策略采纳的效果,而不是实验分流所带来的nudge的效果。这是由业务问题导向的,而不是数据/显著性决定的。
- IV本身无法提升灵敏度或显著性: 在策略存在漏斗的场景下,如果AB实验得到的ITT(reduced-form estimation)不显著,那么工具变量得到的LATE大概率不会显著。
- 假设
- AB实验分流信息本身是完美的工具变量;我们只需要知道实验组中complier比例即可估计全部因果效应
- 对于同一个内生变量/策略,使用不同的工具变量也会得到不同的LATE,这主要是因为不同的工具变量会得到不同的compliers,所以不同的IV在不同的人群上生效,当然估计出来的treatment effect也会有所不同。
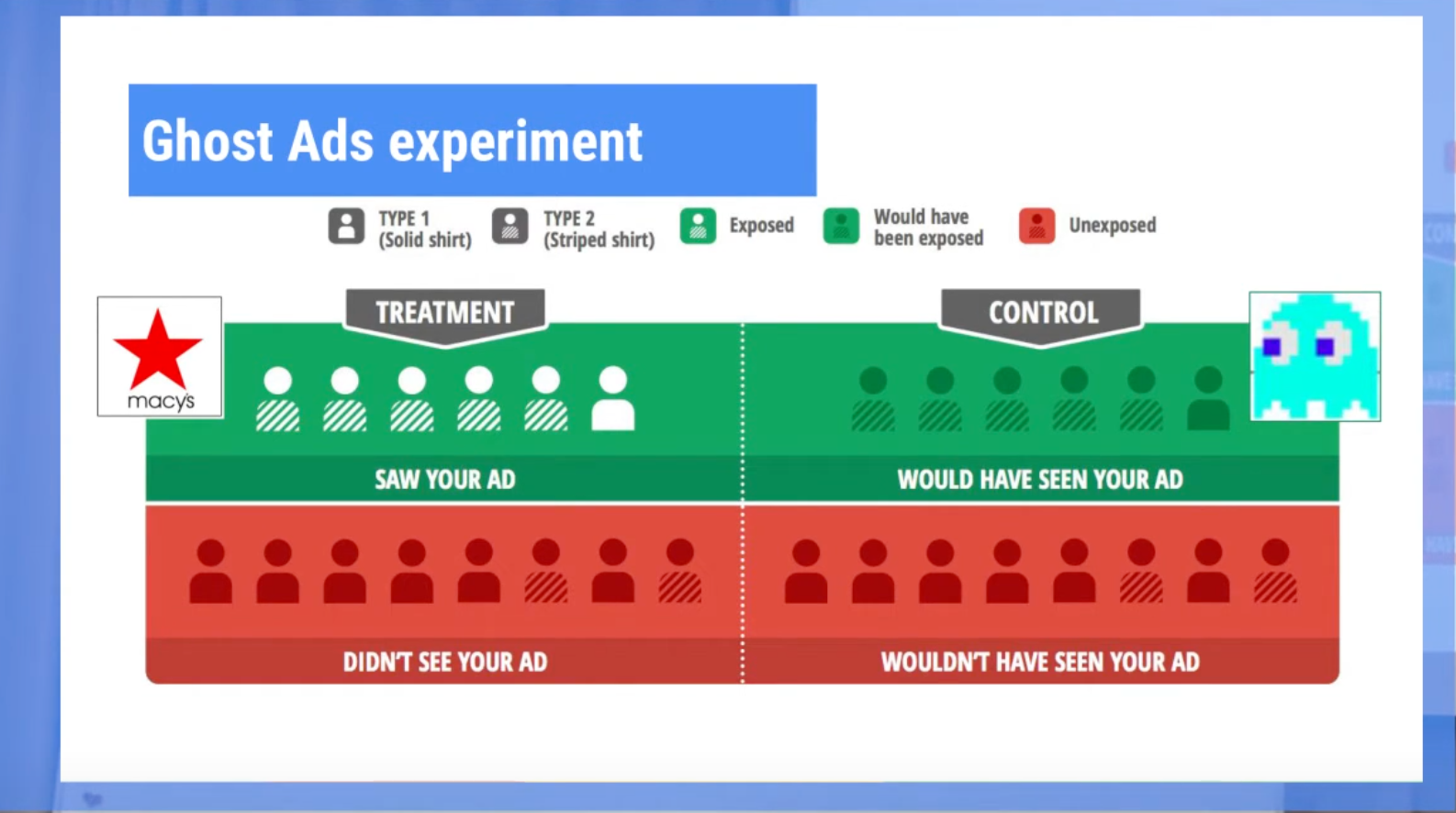
- 反事实Logging (Conterfactual Logging): 通过某种机制定位出对照组可比人群B(例如让模型预估两次)
- 可以大幅缩减方差来估计ATT
- 工程成本较高
- 例如 广告场景用的“染色”机制(Ghost Ads, Reference: (Johnson, G. A., Lewis, R. A., & Nubbemeyer, E. I. (2017). Ghost Ads: Improving the Economics of Measuring Online Ad Effectiveness.,youtube))
-
- 例如 广告场景用的“染色”机制(Ghost Ads, Reference: (Johnson, G. A., Lewis, R. A., & Nubbemeyer, E. I. (2017). Ghost Ads: Improving the Economics of Measuring Online Ad Effectiveness.,youtube))
- 局限性
- 染色的阈值:提出了染上一次色是否是推荐系统的偶然现象,以及染几次色才算真正可比的疑问
- 策略的干扰:指出第一次染色后,由于频控等策略,对照组染色的概率会更高,因此实验不能持续太长时间
- 匹配法
- 通过实验前特征等在对照组中找出可比的对照组B1(例如PSM等方法)
- 预估有偏差,但可以提升灵敏度
- 常和IV配合使用(两阶段估计)
如何结合IV和匹配(PSM)方法?
IV校准] H --> I{显著?
且通过IV检验} I -- ✔ --> J[输出ATT] I -- ❌ --> K[策略无显著效果
优化策略重启实验] style D fill:#d4efdf,stroke:#2ecc71 style G fill:#d4efdf,stroke:#2ecc71 style J fill:#d4efdf,stroke:#2ecc71 style K fill:#fadbd8,stroke:#e74c3c style A fill:#fadbd8,stroke:#e74c3c
如何和匹配方法结合缩减偏差?两阶段回归为例
假设了策略T和Y之间是线性关系:
在这个假设下,策略效果ATT = 对所有人都是一样的。在这种情况下我们可以推导出利用IV可以得到ATT的无偏估计,用到IV假设A1 - A4:
变量类型 - 无偏估计推理
Y和T都是0,1变量:
\begin{align*} \delta&=\frac{E[Y|Z = 1]-E[Y|Z = 0]}{E[T|Z = 1]-E[T|Z = 0]}\\ E[Y|Z = 1]-E[Y|Z = 0]&=E[\delta T+\alpha _u U|Z = 1]-E[\delta T+\alpha _u U|Z = 0] \ ( \text{Assumption 2 and 4} )\\ &=\delta (E[T|Z = 1]-E[T|Z = 0])+\alpha _u (E[U|Z = 1]-E[U|Z = 0])\\ &=\delta (E[T|Z = 1]-E[T|Z = 0])+\alpha _u (E[U]-E[U]) \ ( \text{Assumption 3} )\\ &=\delta (E[T|Z = 1]-E[T|Z = 0])\\ \delta&=\frac{E[Y|Z = 1]-E[Y|Z = 0]}{E[T|Z = 1]-E[T|Z = 0]} \end{align*}
IV假设1保证了上面的分母。delta是我们想估计的ATT,分子分母中的条件期望都可以通过实验数据中的条件平均值计算出来。
此时如果实验中没有always - taker,那么对照组中就没有T = 1的用户,实验组中E[T|Z = 1]为策略在实验组中的渗透率,此时ATT就等于ITT/渗透率。
Y和T都是连续变量的情况:
\begin{align*} \delta&=\frac{Cov(Y,Z)}{Cov(T,Z)}\\ Cov(Y,Z)&=E[YZ]-E[Y]E[Z]\\ &=E[(\delta T+\alpha _u U)Z]-E[\delta T+\alpha _u U]E[Z] \ ( \text{Assumption 2 and 4} )\\ &=\delta (E[TZ]-E[T]E[Z])+\alpha _u (E[UZ]-E[U]E[Z])\\ &=\delta Cov(T,Z)+\alpha _u Cov(U,Z)\\ &=\delta Cov(T,Z) \ ( \text{Assumption 3} )\\ \delta&=\frac{Cov(Y,Z)}{Cov(T,Z)} \end{align*}
假设1保证分母$\neq$0。
两阶段回归法:各种变量类型都适用
- , ;第一阶段:T对Z回归。
- ;第二阶段:Y对回归。此时是通过一阶段回归由Z映射而来,因此继承了Z的unconfoundedness。
两阶段回归中加入与T,Z相关性高的X可以减小估计方差(与CUPED思路相似)。
线性模型的优点是它可以利用IV帮助我们计算T对Y的无偏ATT估计量,但是它的缺陷也很明显:线性模型假设策略对所有人的效果是相同的
Reference
- What do we mean by triggering in A/B testing?
- Deng, etl, Zero to Hero: Exploiting Null Effects to Achieve Variance Reduction in Experiments with One-sided Triggering
- Deng, A., & Hu, Y. (2015, February). Diluted treatment effect estimation for trigger analysis in online controlled experiments. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining
- Felton, C., & Stewart, B. M. (2022, September 5). Handle with Care: A Sociologist’s Guide to Causal Inference with Instrumental Variables.
- Mostly harmless econometrics, Chapter 4
Heterogenous Treatment Effect (异质性分析)
有时候,关心实验整体效果(ATE)并不能满足我们的需要 例如
- 一个广告策略的实验,由于用户主动选择/推荐策略,触达人群有差异
- 从策略效果,B优于A,但是打平人群对比,A内容质量/转化率优于B
-
Reference
- Braun, M., & Schwartz, E. M. (2023, May 25). Where A - B Testing Goes Wrong: What Online Experiments Cannot (and Can) Tell You About How Customers Respond to Advertising.
实验机制与决策类问题
Long Term Effects (长期效应度量)
受实验成本和迭代速度限制,普通实验评估策略短期效应,但企业更希望度量长期效应。一般假设策略短期效应即可代表长期效应,但并非所有场景都成立
短期效应假设不能代表长期效应可能的原因有
- 用户随时间学习导致处理效应改变(即ATE是时间函数)
- 新奇效应:新鲜的改变一开始引人入胜,能够提升参与度,但是长期会随着时间逐渐消退甚至反向
- 搜索结果不好带来用户重复搜索,query占比和广告收入短期会上升,长期用户离开,收入下降;
- 出更多广告短期收入上升,但用户流失或学会了不点广告,长期收入下降;
- 首位效应:最开始并没有带来正向收益,但是由于用户随时间变化习惯了改动,参与度会提升
- 新奇效应:新鲜的改变一开始引人入胜,能够提升参与度,但是长期会随着时间逐渐消退甚至反向
- 策略效应本身需要时间
- 网络效应延迟:社交或平台类产品的网络效应需要时间积累,短期实验无法观察到临界质量带来的价值
- 行为习惯形成周期:养成新习惯通常需要数周甚至数月,短期实验难以捕捉稳定行为模式的建立
- airbnb从预订到入住时间较长,用户留存的影响很久才能测量出来;
- 长尾效应:某些策略可能对少数用户产生极大影响,但需要长期才能在整体指标上显现
- 跨平台协同效应:用户在多平台间的行为迁移和适应需要时间,短期内难以评估完整影响
- 品牌认知建立:某些变化可能影响品牌认知,这种效应通常需要长时间才能在用户行为中体现
- 生态系统/外部环境变动:新功能上线;季节性;竞争环境改变:比如竞品上了同样的功能;治理政策:如GDPR;Concept driff; 软件退化;都会导致策略效果衰减
方法一:长期实验
直观的方法是把实验时间拉长,通常采用如下分析方法
- 直接分析
-
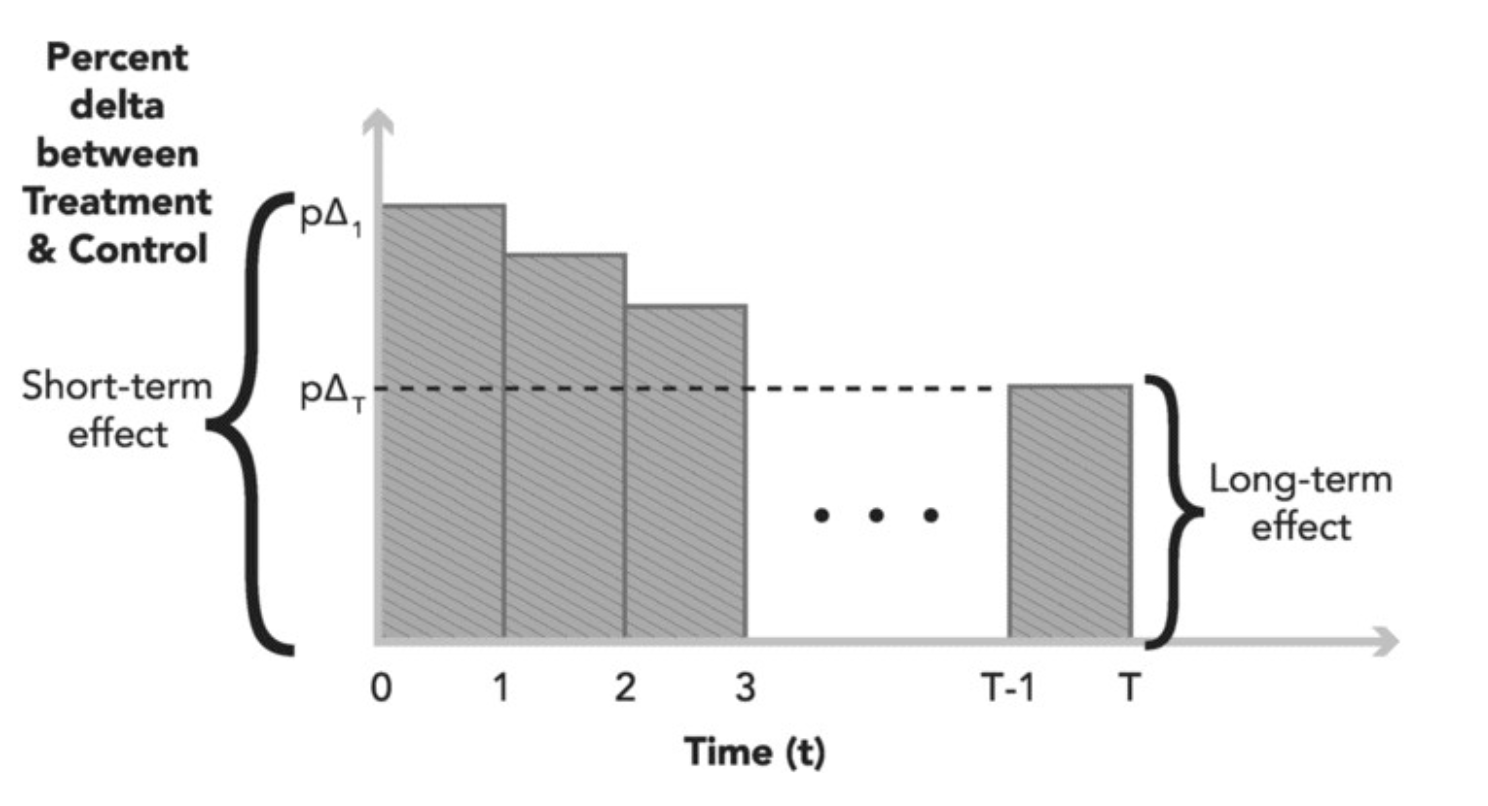
- 对归因来说:效果稀释
- 用户多设备导致的效果稀释;
- 如果是基于cookie分流的,时间越长同一个自然人越可能进入不同组;
- 如果有网络效应,时间越长,leakage会越大;
- 幸存者偏差:如果用户留存有区别,只看最后一周的数据就不能准确反映实验效果;
- 和其他功能的交互效果:实验期间会有很多新的功能上线,会影响现有功能的表现,比如一开始发push很有用,如果其他team也发push,效果就会衰减;
- 如果外部环境变化了,实验效果也会受影响,所以末期和初期的效果diff不一定是效果本身的影响。
-
- Cohort Analysis:分析同一批用户的短期效果和长期效果,可以解决稀释和幸存者偏差的问题,但需要考虑两个问题:
- 先要确定用户群的稳定性,即用什么字段来对应同一个用户,这个字段需要比较稳定才能用这个方法
- 这一批用户是否能代表整体用户,不能的话这个实验的外部有效性就会很低 (例如对于低频业务,先进组的用户可能高活)
- Post-Period Analysis
-
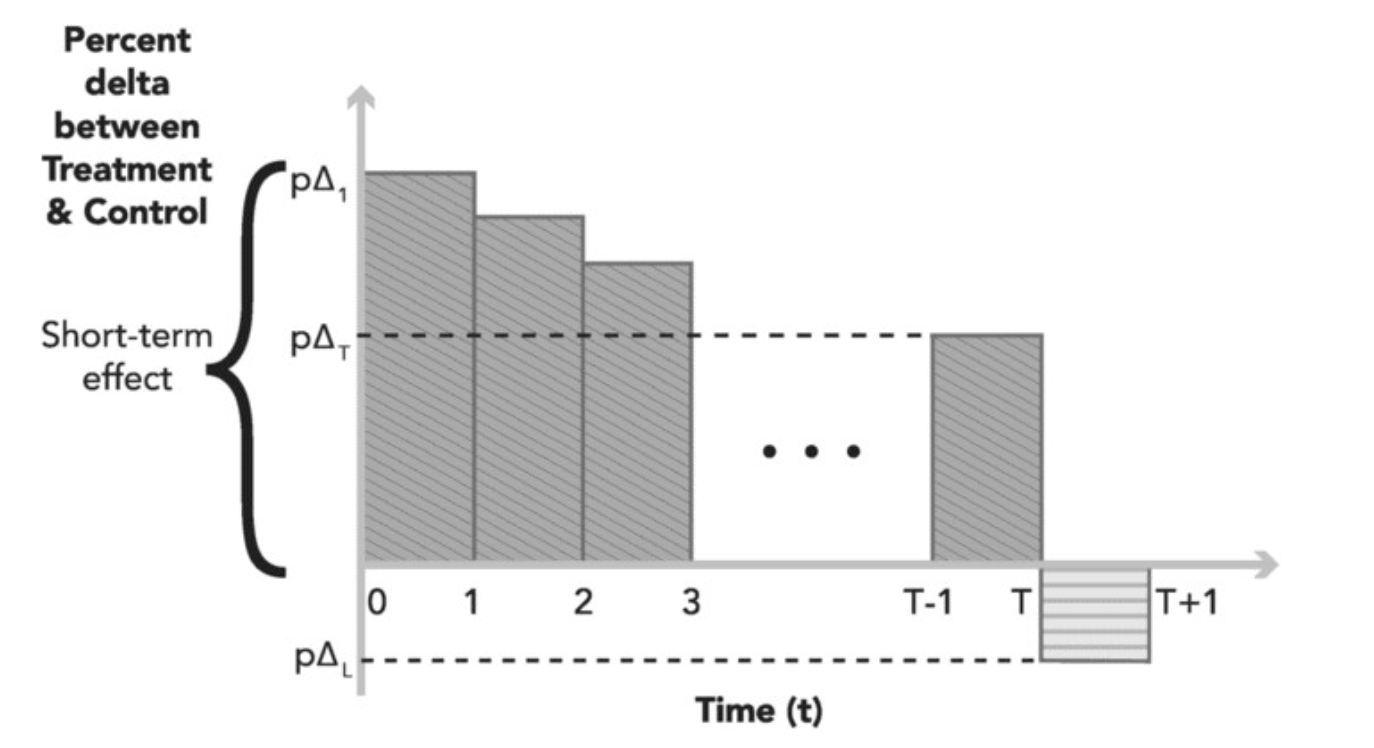
- 在实验关闭后比较实验组和对照组用户的差别,衡量用户学习的影响,在测量时实验组和对照组的treatment是一样的,这么测量的效果即学习效应,可以分成两类:
- 用户习得效应:例如给用户出很多低质广告后,用户学会了少点击广告;
- 系统习得效应:系统“记住了”之前的信息,比如很多依赖机器学习模型的个性化算法,比如一个给爱点广告的人出更多广告的算法,如果实验改动使得用户点击更多广告,那即使实验结束了,仍然会出更多广告。
-
- Time-Staggered Treatments:即两组使用同样的treatment,但开始的时间不一致,比较两组的差别
-
- Holdback and Reverse Experiment
- 试验成本提升
- 实验持续时间太长,没有办法敏捷的做出判断
- 无法控制长期的其他变量不变
- 例如用户随时间变化无法观察到相应数据,或者一个设备上线时间其实是不同用户在使用
- 或一个用户长时间采用不同设备登陆,这些都会污染实验
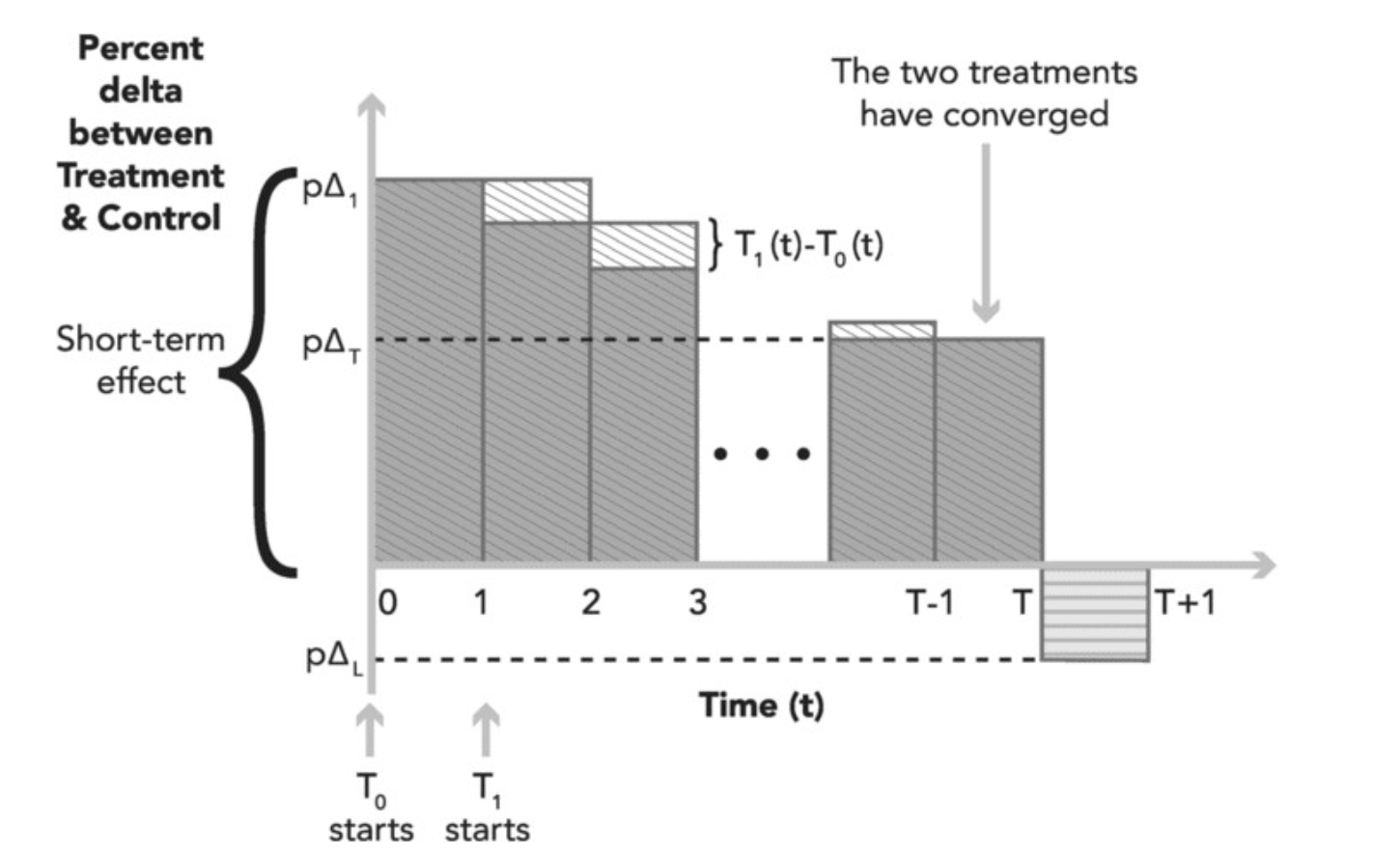
长期实验相比短期实验在开设和观测上有很多难点:
- 分流Cookie稳定性问题
- Cookie Churn: 用户Cookie留存率低(两月实验低于25%留存),可能导致样本流失和选择性偏差
- 避坑:采用UID/Device ID分流或Cookie备份机制
- Cookie Clobbering: 非用户主动清除(如浏览器Bug)导致数据丢失
- 避坑:使用跨浏览器兼容性测试和冗余数据存储
- Cookie Churn: 用户Cookie留存率低(两月实验低于25%留存),可能导致样本流失和选择性偏差
- 实验设计偏差
- 幸存者偏差: 用户流失可能使剩余样本不具代表性(例如高活跃用户留存)
- 避坑:采用抗流失指标(如Click/User)和全周期用户追踪
- 选择性偏差: PP方法可能高估学习效应(例如广告下划线实验)
- 避坑:通过对比长期实验直接观测结果验证短期结论
- 幸存者偏差: 用户流失可能使剩余样本不具代表性(例如高活跃用户留存)
- 效应混淆
- 短期效应与长期效应混杂: 用户学习效应(广告适应)与系统或季节性变化交织
- 避坑:使用CCD方法(下文)量化学习效应趋势
- 副作用残留: 实验结束后可能依然影响用户信息录入或模型反馈等
- 避坑:设计策略回滚监测期和因果影响链分析
- 短期效应与长期效应混杂: 用户学习效应(广告适应)与系统或季节性变化交织
- 外部干扰
- 季节性影响: 大型活动可能干扰学习效应度量(例如格莱美周娱乐实验)
避坑:采用全周期用户分析替代分段观测 - 错误关联感知: 系统变化可能被误判为学习效应(例如浏览器市场份额变动)
避坑:建立系统变更监控基线和多维度归因模型
- 季节性影响: 大型活动可能干扰学习效应度量(例如格莱美周娱乐实验)
- 方法局限性
- Naive Setup: 潜在缺陷在于受系统、季节或交互因素干扰(优化方案:结合反事实预测模型)
- PP方法: 潜在问题为样本流失与选择性偏差(优化方案:缩短Post-period观测窗口)
- CCD方法: 潜在问题是工程复杂且需要更大流量 (优化方案:采用分阶段流量扩量策略)
- 指标设计陷阱
- 比例型指标误导: 如CTR可能掩盖用户流失问题
- 避坑:同时监控绝对值指标(例如总点击量)
- 长期效应拟合偏差: 实验周期内学习效应可能未完全收敛
- 避坑:采用指数衰减模型进行效应外推
- 比例型指标误导: 如CTR可能掩盖用户流失问题
- 关键验证步骤
- 实验前进行AA测试以验证分流均匀性
- 定期检查实验组和对照组的用户画像一致性
- 建立反事实对照组以排除外部干扰
- 对显著结论进行敏感性分析和多方法交叉验证
Reference:
- Trustworthy Online Controled Experiments, Chapter 23 Measuring Long-Term Treatment Effects
- Dmitriev, P., Frasca, B., Gupta, S., Kohavi, R., & Vaz, G. (n.d.).2-16 Pitfalls of Long - Term Online Controlled Experiments.Microsoft Corporation, Redmond, WA 98052, USA. Retrieved from
方法2:Modeling User Learning
- Google提出了一种新的实验机制
- Reference: Hohnhold, H., O’Brien, D., & Tang, D. (2015). Focusing on the Long-term: It’s Good for Users and Business. KDD (pp. 1849-1858)
- 本质上解决了长期效应难以度量(用参数拟合学习效应)和噪声问题(开设时间长,外部干扰因素混入)
- Cookie-Cookie-Day实验机制
-
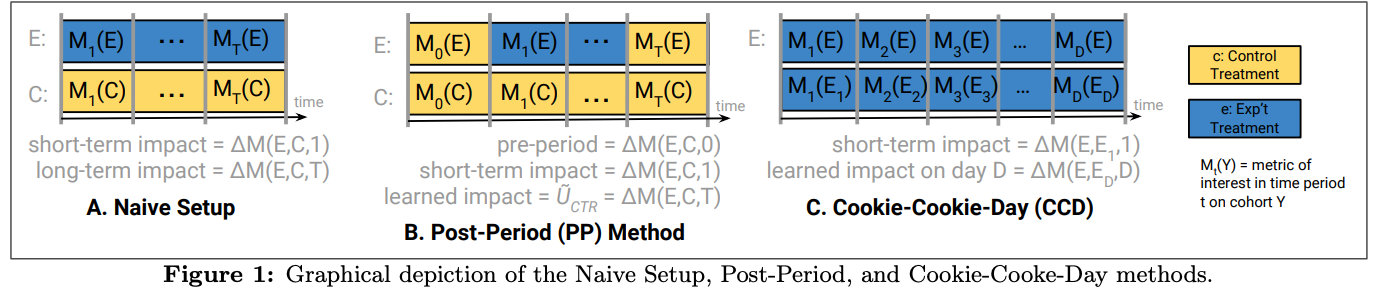
- CCD框架结合了两个并行实验的特点:
- 标准Cookie实验:用户始终处于固定的处理组或控制组中。
- Cookie x 日实验:用户每天都会被重新随机分配到处理组或控制组中。这种双管齐下的方法通过比较持续暴露于实验条件与短暂暴露的群组来隔离长期效应Cookie日实验中的每日重新随机分配创建了一个主要经历基线处理的控制组,使研究人员能够区分即时效应和累计效应
-
- 问题
- 使用模型去拟合更长阶段的残余效应时,的假设一定不合理:本篇论文假设了学习效应参数是0.012,但因为行为曝光的强度会影响用户学习的速度,比如说,搜索更频繁、广告出现更频繁的用户学习的速度更快,也就是不需要那么长的实验时间
- cookie作为识别用户的身份证,会有bias;同一个用户会切换设备,切换不同的浏览器,一些注重隐私保护的用户甚至会定时清空cookie
- 如果条件控制的不严格会出现各种各样的bias(如口碑 用户传播等)
方法3:surrogate Index (短期指标替代长期指标)
找对长期处理效应有因果影响的 driver metrics(短期)并度量它,估计用户学习效应,进而估计长期处理效应变化
Paper1 Athey, S., Chetty, R., Imbens, G. W., & Kang, H. (2019). The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely (No. w26463). National Bureau of Economic Research.
- 形式化了如何将中间结果组合以高效估计长期影响,明确了在何种假设下这种方法产生无偏估计,并正式将基于次级数据集的替代指标与长期结果之间关系的估计纳入考虑
- 开发了对这些假设违反可能导致的偏差程度的可行界限,以及验证这些假设的样本外方法
- 展示了即使在可以直接估计长期处理效应的情况下,使用替代指标也能提高效率
- 提供了一个实证应用,表明使用多个中间结果而非单一预测因子可以将劳动力市场中长期处理效应的预测提前数年,并显著提高精确度
- 主要参考点:
- 完整理论框架与数学证明到实际操作:如何通过观察数据找到替代指标,然后用实验数据(或伪实验数据)进行验证
- 证伪替代/中介作用的方法:留出法(hold out)
Paper2: Yang, J., Eckles, D., Dhillon, P., & Aral, S. (2023). Targeting for long-term outcomes. Management Science. by HBS
- 主要贡献:Paper1的拓展
- 分析性地展示了替代指标(surrogate index)在何种情况下可以有效地替代真实但无法观察的长期结果进行政策评估和优化
- 通过实证验证了该方法:
- 进行了两个大规模实验,确定应该针对哪些用户提供什么样的激励,以最大化《波士顿环球报》的长期订阅收入
- 结合第一个实验的数据和时间推移,证明了基于替代指标推断的长期结果优化的政策优于基于短期代理指标优化的政策,并且其表现与基于真实长期结果优化的政策相似
- 实施了优化政策,并加入额外的随机探索,以便应对潜在的非平稳性,并在每次实验后更新优化政策
- 主要参考:
- Surrogate Index的理论框架需要满足的假设
-
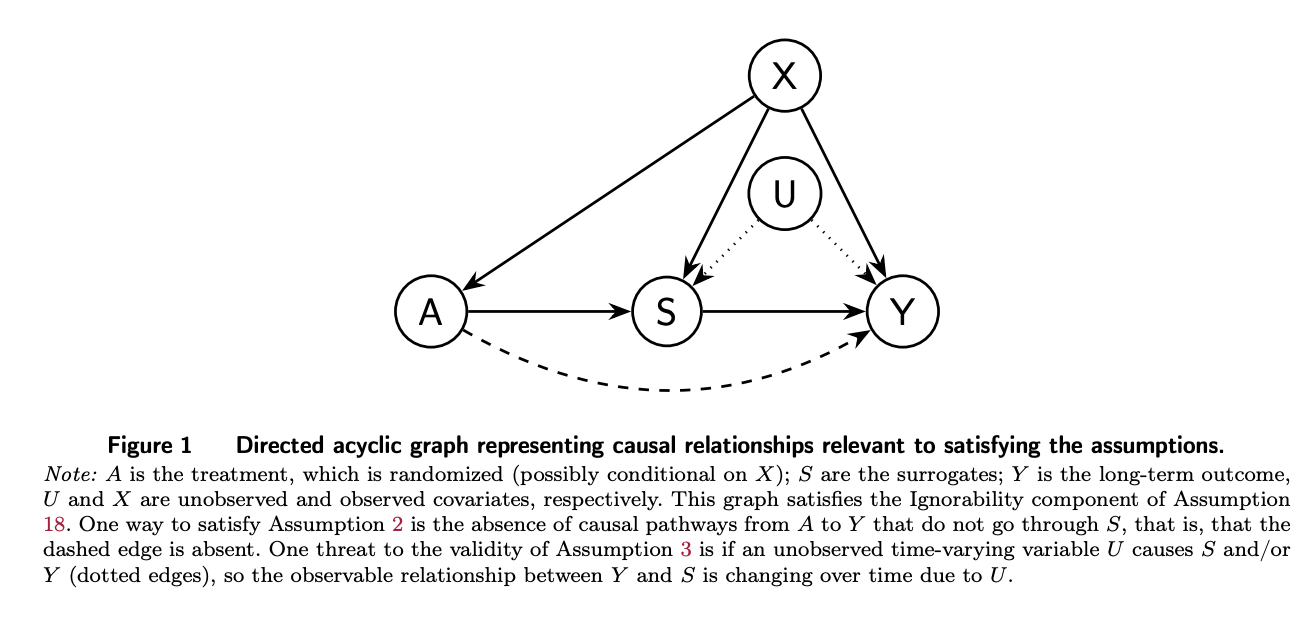
- Unconfoundedness(等价于Ignorabiity, Positivity):通常的因果推断假设
- Surrogacy Condition(完全中介):只能证伪,paper1提出了一种方法
-
- Comparability:条件于协变量和替代指标的长期结果分布在实验数据集和历史数据集中是相同的
- 实际应用时不能与训练或制定规则时的分布发生偏移
-
- 实际应用时不能与训练或制定规则时的分布发生偏移
-
- 实操过程(结合paper1)
- Surrogate Index的理论框架需要满足的假设
Paper3: Wang, Y., Sharma, M., Xu, C., Badam, S., Sun, Q., Richardson, L., … & Chen, M. (2022, August). Surrogate for long-term user experience in recommender systems (pp. 4100-4109)
, Google Research
- 研究了一系列连续的用户行为模式,并标准化了一个流程,用于精确定位那些对用户长期访问频率变化具有强预测能力的行为子集
- 测量:提出了一套指标,用以捕捉用户的顺序性和时间性的消费行为模式。
- 分析洞察:识别了一组与用户长期体验相关的用户行为模式。
- 替代指标的选择:标准化了选择用户行为模式作为长期用户体验替代指标的过程,该过程基于稳健的预测模型。
- 算法改进:验证了在强化学习推荐系统中,通过替代指标优化长期用户体验的有效性。
- 主要挑战在于确定用户的真实兴趣,而不仅仅是根据用户曾经消费过的主题来进行推断。
- 这需要定义一个度量来捕捉用户的真实兴趣,以便在推荐系统中提高长期用户体验。
- 主要参考:
- 代理指标 如多样性的定义、有效/高价值消费(卡阈值 xxx代表建立“心智”)、类目发现性及复访(复购)频次
- 前置数据分析:需要验证路径一致性
- 指标选择方法:用tree
- 验证方法:reward experiment(EE/RF开长期实验)
Paper4: Duan, W., Ba, S., & Zhang, C. (2021, March). Online Experimentation with Surrogate Metrics: Guidelines and a Case Study). LinkedIn
- 主要参考
- 文章的“Surrogate Metrics" 和前面三篇的Surrogate Index不完全是一个概念,更接近于验证在实验中使用预估值代替后验值的可行性(例如用预估LTV代替后验LTV)偏实操
- 实操原则
- 选择北极星指标的指导原则(定性规则)
- 对真实北极星指标具有高预测能力(如 、AUC 等指标)
- 专注于我们可以在短期内改变和测量的指标(分析历史实验中的撬动作用)
- 针对不同处理特征进行定制化(跨渠道、用户等定义一致的指标)
- 可解释性(如果是模型,代理指标的涨跌最好能归因)
- 管理开销(最好是简单规则,避免需要持续训练且难以解释的模型)
- 实验方差需要修正,代理指标的方差通常比实际小,要考虑预测环节本身的方差
-
- 如何验证替代条件(surrogacy condition)
- 验证 W -> S -> Y 是唯一通路(中介变量)等价于 ((注意作者没有特别控制其他变量,而是所有信息都包含在 S 模型中))
- 在现实应用中,使用历史实验数据来确保两者偏差不要太大
- 选择北极星指标的指导原则(定性规则)
其他方法
统计性解法方案:
- 把长期处理效应看作异质性处理效应带来的偏差,根据HTE推导出某一类群体的偏差ATE的bias-adjusted jackknife estimator
- References
- Günter J Hitsch and Sanjog Misra. Heterogeneous treatment effects and optimal targeting policy evaluation. Working paper, 2018.
- Eva Ascarza. Retention futility: Targeting high-risk customers might be ineffective. Journal of Marketing Research, 55(1):80–98, 2018.
- References
- 双边市场场景下,利用sequential testing和强化学习来验证长期处理效应
- 因果推断相关
- Marshall M Joffe and Tom Greene. 2009. Related causal frameworks for surrogate outcomes. Biometrics 65, 2 (2009), 530–538.
- Ross L Prentice. 1989. Surrogate endpoints in clinical trials: definition and operational criteria. Statistics in medicine 8, 4 (1989), 431–440
- Christopher J Weir and Rosalind J Walley. 2006. Statistical evaluation of biomarkers as surrogate endpoints: a literature review. Statistics in medicine 25, 2 (2006), 183–203.
- 推荐系统相关方法
- Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In ICDM’ 18. IEEE, 197–206.
- Raghav Pavan Karumur, Tien T Nguyen, and Joseph A Konstan. 2018. Personality, user preferences and behavior in recommender systems. Information Systems Frontiers 20, 6 (2018), 1241–1265.
Reference: Lassen, et al, 2022. Statistical Challenges in Online Controlled Experiments: A Review of A/B Testing Methodology
Optional Stopping (连续实验问题)
连续实验问题主要关注如何在不损害统计效度的前提下提前结束实验。企业希望快速筛选出有正向影响的策略,同时尽早摒弃负向影响的策略。由于实验结果通常可以近实时观察,研究人员容易产生"窥视"(peeking)行为——即连续监视p值并在达到显著性时立即停止实验。这种做法虽然能降低实验成本,但会显著提高假阳性率(一类错误)。因此,我们需要一种能在控制一类错误率的同时允许提前决策的实验终止机制。
peeking问题:连续观测会引起一类错误率膨胀:每天都做了一次假设检验,犯错概率5%,连续做了N天的假设检验,整体犯错率为1-(1-5%)^n >5%
Sequential Testing
- 通过降低每一天/次假设检验的一类错误率,保障多次假设检验的总一类错误率不超过5%
- 优点:可以控制一类错误率,避免碰巧显著而关停实验带来的一类错误率膨胀;
- 缺点:
- 也有一些不适用场景,例如多个指标检测;降低HTE功效
- sequential testing会降低统计功效,根据optimizely的数据该方法大约会带来36%的统计功效损失
- 为解决sequential testing降低统计功效的问题,我们将实验分为两个阶段:
- 观察监控时期:从实验开始到结束前一天,使用保守的sequential testing方法进行连续监控。只有在效果特别显著且满足最小观察周期时才做决策,重点控制一类错误率。
- 决策时期:实验结束后,使用传统的固定样本检验方法进行全面分析和决策,更注重统计功效。这种方法既能控制整个实验过程中的一类错误率,又能在决策阶段保持较高的统计功效,平衡了早期监控的安全性和最终决策的灵敏度。
- 该方法需要对潜在因果的分布有先验知识,因此实际应用受到局限
- optimizely的论文中,假设先验分布是均值为0的正态分布,方差未知,但是可以通过历史实验中true treatment effect进行估计,这是概率论估计思路的方法。这种方法的好处是和sequential testing这套思想完全契合。
- 另一种方法是转化成优化问题。在控制一类错误率的部分,我们发现这个部分参数的先验分布本身并无任何限制,也就是说不管我们是使用方差为多少的正态分布,哪怕甚至是均匀分布、lognormal分布…不管是什么样的先验分布我们都可以通过鞅的性质对一类错误率进行很好的控制
- 也有一些不适用场景,例如多个指标检测;降低HTE功效
具体方法:
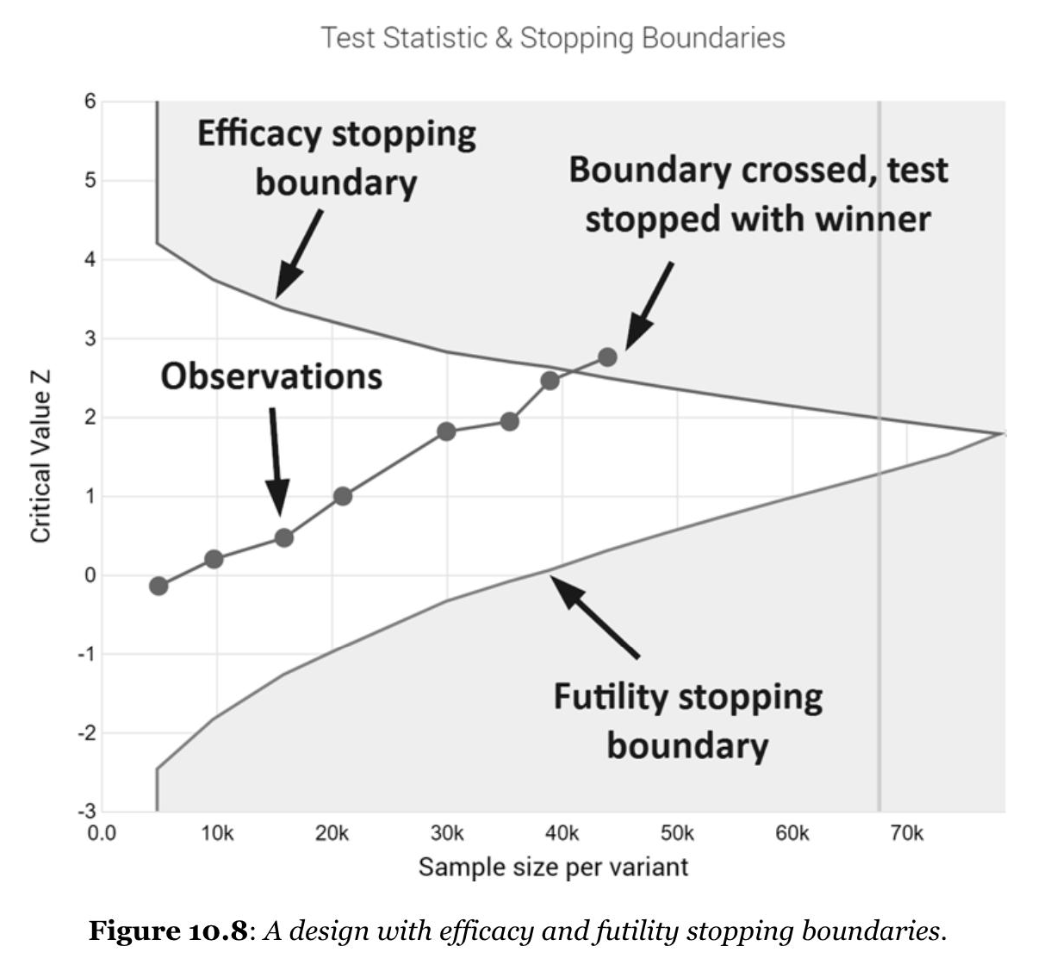
- sequential probability ratio test (SPRT)
- (0 < B < A, B = \frac{\beta}{1-\alpha}, A = \frac{1 - \beta}{\alpha});假设分别为:(H_0 : \theta = \theta_0, H_1 : \theta = \theta_1);
- likelihood ratio test statistics:(\Lambda_n = \prod_{i = 1}^{n}\frac{f(y_i|\theta_1)}{f(y_i|\theta_0)})
- 通过A、B两个值,拒绝域将样本空间划分为三个决策规则:
- 如果(\Lambda_n > A),拒绝(H_0),停止实验;
- 如果(\Lambda_n < B),无法拒绝(H_0),停止实验;
- 如果(B < \Lambda_n < A),积累实验样本,计算(\Lambda_{n + 1});
- 统计原理
- 当H_0成立时统计量LR是鞅(martingale),会在1的附近随机波动,因此可以通过随机过程中鞅的性质来控制一类错误率。以b作为判断LR是否显著的阈值,LR>b则认为检验有显著结论。假设首次得到显著结论是在第T_b次检验,那么有如下性质,即在任意多次检验范围内犯一类错误的概率不超过1/b。那么当我们以1/alpha作为监控阈值,那么一类错误率就可以被控制在alpha的范围内,也就是说在H_0的时候就算我们无限制的等下去也只有5%的概率会误报。
- 这里出现了一个很尴尬的问题:我们并不知道实际上实验有没有效果,H_0成立的时候95%概率下我们等一辈子也不会有显著效果,这可怎么办呢?因此我们采用截断的方法(truncation):即我们设定一个截止时间,到这个时间的时候如果还没有显著的结论那我们就认为这个实验确实没有效果,同时停止实验。
- 如图、上面那一条「reject null if crossed」用来判断是否拒绝原假设,一旦高出这条线,实验结束,称之为 Efficacy Boundary;下面那一条「accept null if crossed」用来判断是否确实无需继续等待结果显著,一旦低于这条线,实验结束,称之为 Futility Boundary,顾名思义是来避免资源浪费的。
- 在此基础上,又延伸出mixture sequential probability ratio test (mSPRT)和generalized sequential probability ratio test (GSPRT)
- Group Sequential Trials (GST): 在实际情况中,基本都无法做到「连续地」做检验(每新增一部分数据就做一次检验),这样成本太高而且在 AB test 中是不可能实现的。在 GST 中,把全部数据分成几部分(group),分别对每一部分的数据做检验,然后再把这些检验结果合在一起
- 如何选择Decision Boundaries: 越多样本积累、越激进
- 要求:分析的时间间隔一致:比如如果做两次分析,那么第一次、第二次分别用到全部信息量的50%、100%;如果做四次分析,那么四次分别用到全部信息量的 25%、50%、75%、100%;做几次分析、分析的时间节点,都需要事先确定
- 一些改进的方法:spending function(医学领域)
- Group Sequential Trials (GST): 在实际情况中,基本都无法做到「连续地」做检验(每新增一部分数据就做一次检验),这样成本太高而且在 AB test 中是不可能实现的。在 GST 中,把全部数据分成几部分(group),分别对每一部分的数据做检验,然后再把这些检验结果合在一起
sequential testing的方法在业界有被广泛应用,Netflix(Group Sequential)、optimizely、蚂蚁、libra用户侧都采用了该方法。除此之外,针对peeking业界和学界也有其他不同的处理方法
| 名称 | 理论方案 | 实际场景 | 优点 | 缺点 |
|---|---|---|---|---|
| p - value曲线(libra现有方案) | 在连续多天查看报表显著性的情况下,"综合考虑连续多天的显著性,稳定显著再决策"比"只考虑连续多天内某一天的显著性,一天显著就决策"犯一类错误的概率更小,通过"改变稳定显著的决策逻辑"可以将一类错误率控制在预期alpha水平 | 通过「p - value曲线稳定显著」做决策可以控制整体一类错误率不过分膨胀。最佳决策逻辑:第1天<2*alpha,第2、3天<alpha | 1. 工程实现起来方便 2. 对实际一类错误率的控制不够灵活,一类错误率仍存在稍高于预期的可能性 |
1. 用户理解、使用有成本 |
| mSPRT(Netflix) | 每组样本内,假设所有样本点独立同分布。重新构造p - value的计算方式,使得无论何时进行观测,观测到的p - value总是控制在预期alpha以内;理论上利用鞅的性质可以证明上述结论 | Online A/B testing场景中,"用户复访"这一大特点可能会导致: - 对于mSPRT来说:"重新构造的p - value"不再具有鞅的性质,也就意味着存在一类错误率超出预期alpha的风险 |
1. 用户可实时观测,方便使用 | 1. 实际场景与理论假设存在差异,主要是"用户复访"的问题 |
| GST | 每组样本内,假设所有样本点独立同分布。给定整体实验周期中预期观测次数N,基于已有样本量或固定各观察阶段样本量调整alpha,控制各阶段的一类错误率,进而保证整体的一类错误率不超过alpha | - 对于GST来说:一方面,用户在各个时期的行为跟他自身前期的行为有一定关系,分阶段调整alpha的方法所依赖的样本独立性假设被打破;另一方面,用户有进组的先后顺序,随着时间的积累,可能会出现用户体验不一致的情况,样本点之间不再满足同分布假设。 用户复访:第一天的用户,也可能会在第二天第三天再次出现 |
1. 用户可定期观测,可控性强 | 1. 理论方案主要基于小样本,实际场景数据量巨大,导致工程成本较高 2. "用户复访"问题 |
Reference
- Matwin,Yu, Farooq, Peeking at A/B Tests: Why it matters, and what to do about it, KDD17
- Sequential Test, Wikipedia
- Wald, Abraham (June 1945). "Sequential Tests of Statistical Hypotheses". Annals of Mathematical Statistics. 16 (2): 117–186. doi:10.1214/aoms/1177731118. JSTOR 2235829.
- Georgiev, G. Z. (n.d.). Statistical methods in online A/B testing: Statistics for data - driven business decisions and risk management in e - commerce. Chapter 10. Sequential Testing
- Why you should choose sequential testing to accelerate your experimentation program, Optimizely
- Leonid Pekelis, The story behind our Stats Engine, Optimizely
- Optional stopping theorem
- Improving Experimentation Efficiency at Netflix with Meta Analysis and Optimal Stopping, Netflix
Bayesian A/B Testing
Bayesian testing不会出现p-value hacking的问题:在Bayesian testing框架下,实验者采用fdr来描述错误率,即当我们决定要拒绝原假设时,这个决策是错误的概率有多大,false positive count/ positive count
- 用bayes直接得到了待估参数的后验分布及相应的后验区间估计,更符合正常人对概率和区间正常逻辑的理解。同时,bayes可以产出probability to be the best和probability to beat the baseline等实验结论指标,可以直接避免传统假设检验中多重比较风险(multiple comparison problem)、常观察风险(peeking problem)、多组择优(be the best)的问题。
- 正因为bayes的决策自动化、低用户理解成本、低实验成本等原因,越来越多的互联网公司在条件许可的情况下更多地应用了bayes theorm进行A/B实验分析决策。
- 方法
- Traditional Bayesian Testing
- 根据历史经验给出参数先验分布,通过不断搜集样本来更新参数后验,最终从后验分布生成随机数,模拟得到产生最优指标的概率
- Objective Bayesian Testing
- 结合先验信息进行假设检验,原假设为diff等于0,备则假设为diff服从某个先验分布,并且根据先验知识得到原假设成立和备则假设成立的概率。通过不断收集样本,更新原假设和备则假设成立的后验概率,最后直接比较两个后验概率进行决策
- Traditional Bayesian Testing
- 难点
- 先验选择:先验选择不当会使实验漫长或错误率高;不控制假阳性频率,易检测出更多 “赢家”,因未强力控制错误发现率,其表现取决于先验分布选择;无偏好可以选择均匀分布
- evidence计算:likelihood和prior可以进行无数种不同组合,再加上theta有多个时导致积分空间变为高维空间,这个积分式不保证能进行解析计算,解决的方法有两种:
- 使用conjugate function(posterior和prior属于同一个function family)。Math trick,非general solution。对于binom适用(这也是demo用binom做的原因之一)。
- 使用数值方法计算:数值方法需要我们根据任意给定的(高维)概率分布实现抽样(困扰统计模拟的核心问题之一,有一篇很好的blog来帮助理解)。实践中是由Metropolis族的MCMC算法(如Gibbs)来实现,后者由Markov Chain的长期稳态性质保证随机均匀
- 可以做什么
业界最佳实践
- VWO, Bayesian Whitepaper
- VWO, Maximize Website Conversions
- Optimizely, Multi-Armed Bandit
- Meta, Efficient tuning of online systems using Bayesian optimization
- Uber, Under the Hood of Uber’s Experimentation Platform
Reference
- Alex Deng, Jiannan Lu, Shouyuan Chen, Continuous monitoring of A/B tests without pain: Optional stopping in Bayesian testing
- Alex Deng, Objective Bayesian Two Sample Hypothesis Testing forOnline Controlled Experiments
- Statssig, When to use Bayesian experiments: A beginner’s guide
- Statssig, Bayesian Experimentation
Interference (实验对象之间的互相干预)
Stable Unit Treatment Value Assumption(SUTVA):SUTVA 指的是分流单位之间互不干扰,这是AB实验结论可信的一个前提。在用户粒度分流场景中,SUTVA 指的是:某个用户的行为不会干扰到其他用户受实验变量影响的情况。如果违反了 SUTVA ,我们称之为 interference,a.k.a spillover/linkeage
直接从字面意思上也很好理解——由于实验组和对照组用户之间产生了关联,使得实验组的策略「溢出」到了对照组,导致对照组用户感知到了他本不该感知到的策略,从而使得实验效果被低估和高估。
实验单位间直接联系
典型案例如社交网络,男生把新表情包发给女生时,对照组中的女生感知到了实验策略;微信新表情包只在IOS更新上、命中安卓用户等
- 方案1:规避网络效应–只使用未被网络效应污染的数据
- Reference:A Method for Measuring Network Effects of One-to-One Communication Features in Online A/B Tests
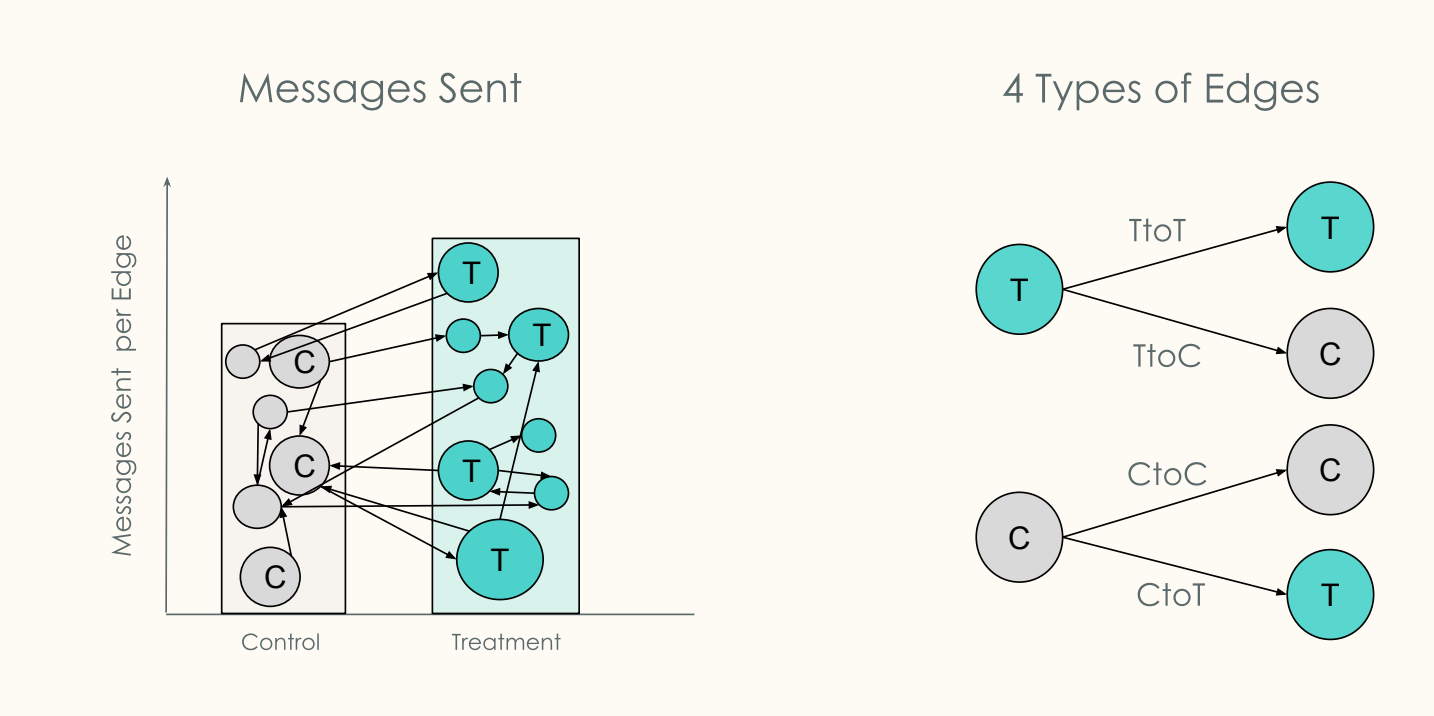
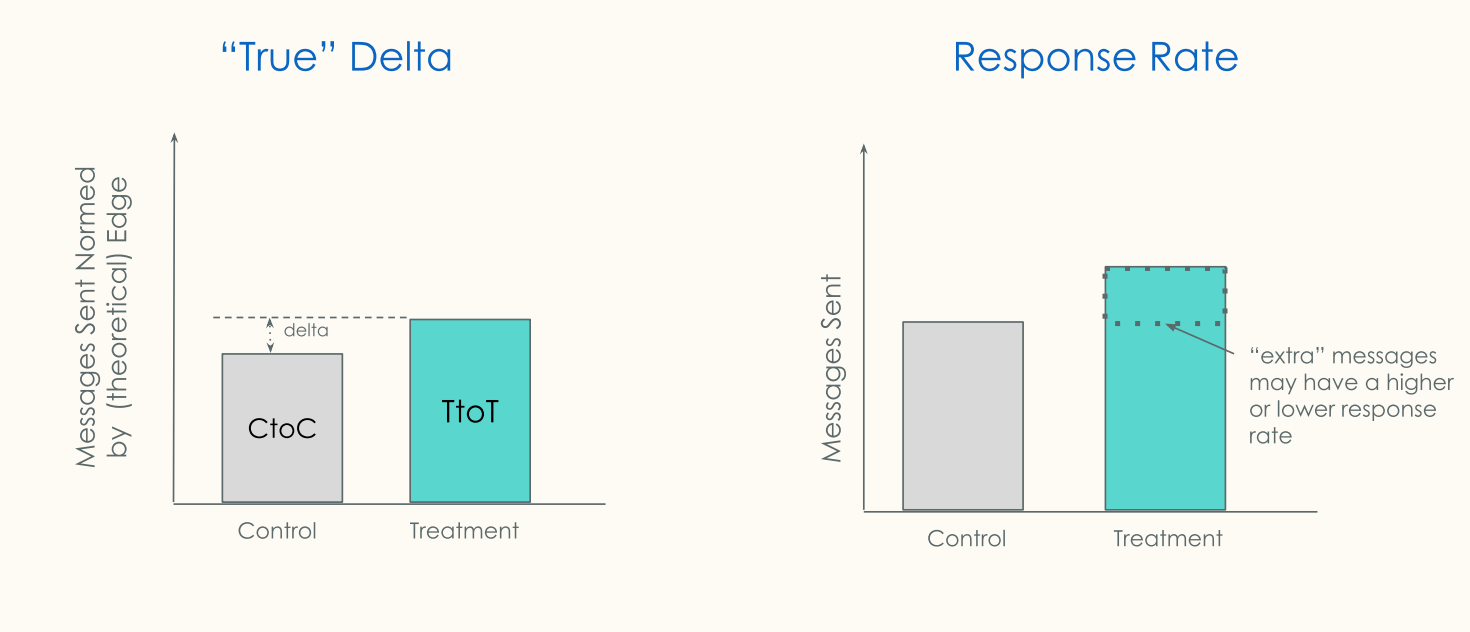
- 对所有的 edges(边)都做好标记之后,在实验进行中我们就可以对以上三种类型的关系分别统计发信息、互动等动作的数量(如果衡量指标是互动量的话),并通过对比「实验组-实验组」、「对照组-对照组」两类 edges 上的互动量来推算出真实的互动量 diff。该方法有一个假设是No treatment affinity,即T-T用户并没有比其他用户更活跃/更不活跃。
-
- 方案2:人群分流(Cluster-based Randomization)
- Refenrence
- Gui et al. 2015, Network A/B Testing: From Sampling to Estimation
- Saveski et al. Detecting Network Effects: Randomizing Over Randomized Experiments
- 按照社交关系给用户画出社交圈子,再对这些圈子进行分流,这样就可以尽量减少实验组和对照组之间的相互影响。
-
- Refenrence
- 方案3:
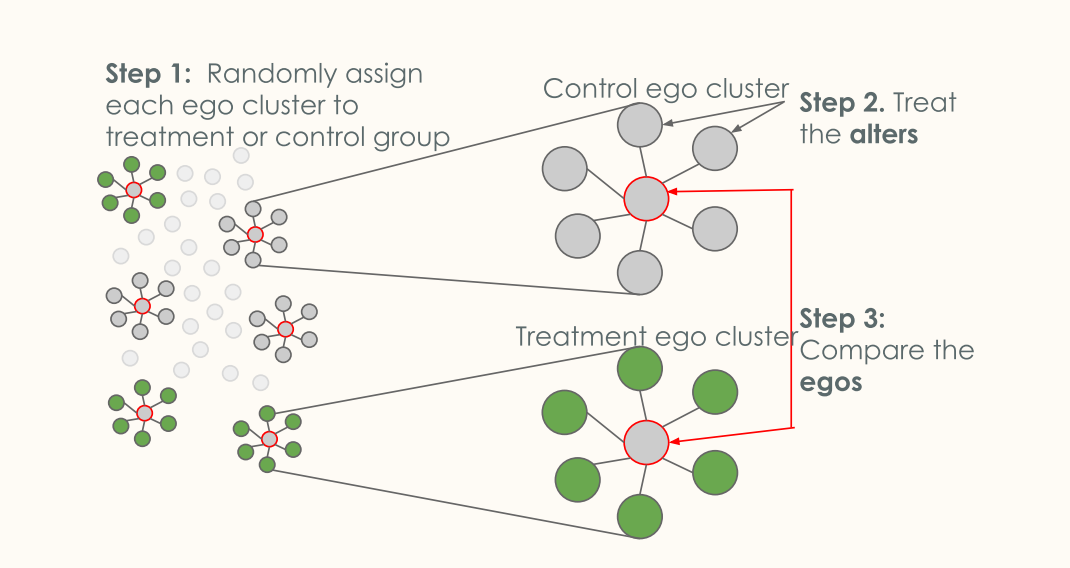
- Reference: Saint-Jacques, et al. Using Ego-Clusters to Measure Network Effects at LinkedIn
- 人群分流只能缓解一部分的相互影响,在上图中也可以看到,cluster之间实际上也还是存在联系的。因此转变思路,不再考虑如何规避网络效应,而是允许它存在并衡量出来。
- 将用户聚合成cluster并对cluster进行分流:所有cluster的中心都是control,不同的是一部分cluster中其他所有用户都是treatment,另一部分其他用户都是control。此时treatment/control的中心用户的差别可以认为是网络效应的影响效果
-

间接联系:双边市场
互联网平台通常具有双边市场属性
| 平台类型 | Supply 生产者 | Demand 消费者 |
|---|---|---|
| 电商平台 | 商家 | 买家 |
| 短视频平台 | 达人(内容生产) | 用户 |
| 广告 | 流量(人x广告位) | 广告主 |
| 外卖 | 餐厅,骑手 | 买家 |
| 酒旅 | 酒店商家 | 买家 |
双百年市场存在两种常见干预
- 共享资源:例如AB组(作者或广告)共享一笔营销预算;共享一个模型(模型学习效果会反映到AB组)
- 相对比较好处理,可以在AB组间隔离或打平预算
- 互相竞争:互相争夺资源
- 对于需求方稀缺的平台,需求侧实验是无偏的,供给侧实验是有偏的。比如直播平台,一个直播间可以服务无限多的人,所以供给无限,主播共同竞争作为需求方的用户
- 对于供给方稀缺的平台,供给侧实验是无偏的,需求侧实验是有偏的。比如早高峰的西二旗地铁站,需要乘车的人非常多,早高峰时段接近无限需求,乘客共同竞争作为供给方的地铁。实验不同的车厢填充策略是无偏的,但是实验不同的乘客排队策略是有侵蚀效应的
- 对于供需关系处于中间态的平台,有偏的情况会比较复杂。比如Airbnb,各个地区的供需关系不尽相同
| 实验场景 | Interference |
|---|---|
|
|
|
|
|
|
方案1:类似直接干预中的社交关系分流/物理隔离
- 对于用户之间强联系的维度进行聚类(eg 出租车/酒店主要在一个城市,生活服务在poi/地理位置)成cluster,同cluster用户在实验/对照组
- 例如对于打车业务,最直接减少干预的方法是改变实验颗粒度,从用户->区域->街区->城市;代价是方差变大(减少bias增大varaince)
- 参照前文社交分流方法开设实验
- 对于模型,有在不同流量间拆分模型的技术(self-train)样本隔离等
- 一些其他技术手段减少组间互相影响,例如Facebook Seller-Side Ranking 迭代,先分别排序,再混合成一个结果,减少组间干预(Reference: Ha - Thuc, V., Dutta, A., Mao, R., Wood, M., & Liu, Y. (n.d.).2020, A Counterfactual Framework for Seller - Side A/B Testing on Marketplaces. Facebook Inc., Menlo Park, CA.)
- 或开设两个实验,用户粒度-cluster粒度,并根据进行纠偏
- Reference: David Holtz, Ruben Lobel, Inessa Liskovich, Sinan Aral, Reducing Interference Bias in Online Marketplace Pricing Experiments (Airbnb)
- B是所在cluster,M是两种实验的diff,v代表了实际SUTVA是否违反
-
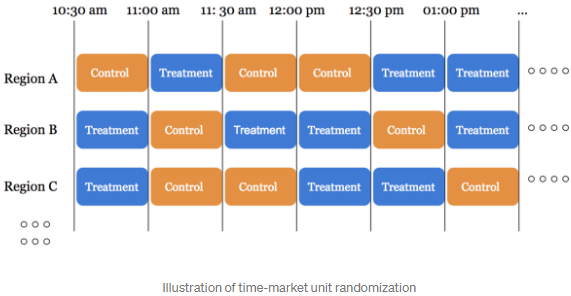
方案2:时间隔离/时间片轮转实验(Switchback Experiments)
- 例如外卖平台通常面临的局面是
- 骑手缺少 → 导致用户无法满足消费需求 → 消费者等待时间过长。
- 需求问题需解决:如何提高用户留存和选择所属时长。
- 为了解决这一问题,Doordash 需要能够通过 增量评估 delivery fee(提升价格)来分析其对用户的具体影响。在上述场景下,使用传统实验对消费者进行精准分流是难以准确评估策略结果的
- Switchback testing的核心思想是, 对于某一区域,随时间推移,在实验组和对照组之间交叉切换。即:对于不同的区域设不同时间段分桶,再对其实验组time bucket和对照组time bucket之间的差异,来评估策略效果
-
- 方差通常通过Sandwich Estimator技术来计算
-
- 问题:
- 增加了variance,换句话说,通常都有power不足的问题
-
- 信息利用率较低
- 检验效率都是比较低的:只选择连续treatment/control的unit进行分析,这就导致了其他剩余流量的浪费; 或进行bucket处理,即把用户打包成bucket(比如说region)当作unit进行分析。这都会导致功效的浪费
- carryover假设过强:假设策略对用户是没有留存影响的,但不太符合实际情况;推策略上线实际上最终想获得的就是持续的长期的收益。方法2没有单独处理carryover的问题。
-
- 该两类实验的设置还让可能出现的偏流客会,会造成一定程度未监管风险。若操作不当,会引入额外的bias
- 增加了variance,换句话说,通常都有power不足的问题
Reference
- Uber Express: A Case of Study
- Case study paper on switchback design (2021): “Unbiased Experiments in Congested Networks”
- Holtz et al. (2020) “Reducing Interference Bias in Online Marketplace Pricing Experiments”
- Spang et al. (2021) “Unbiased Experiments in Congested Networks” – A real application to show how switchback design mitigates spillover effect
- Bojinov, et al, 2020, Design and Analysis of Switchback Experiments
- Doordash: Experiment Rigor for Switchback Experiment Analysis
方案3:双边实验
-
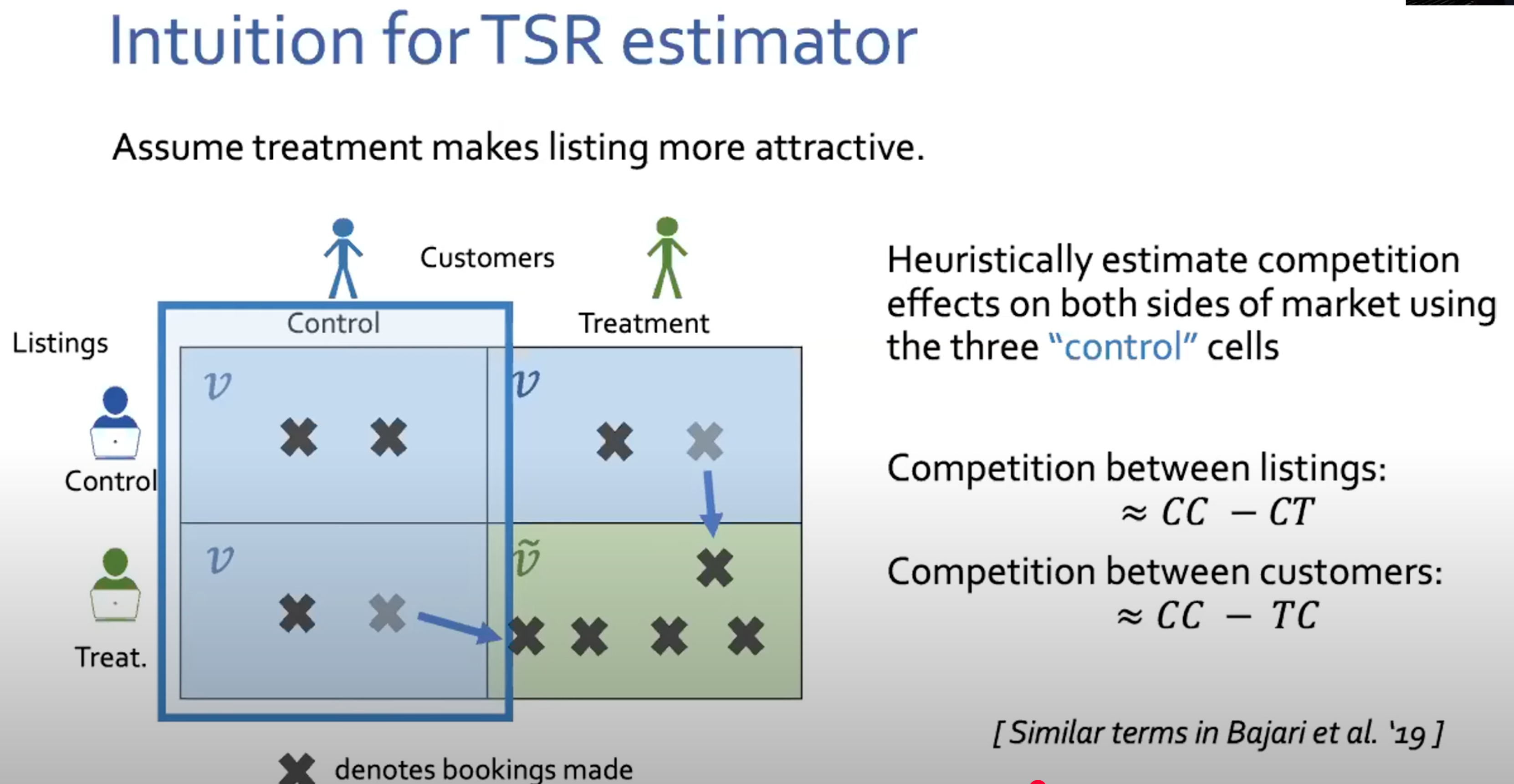
TSR(双边实验,Two-sided Randomization)
- 同时开设双边分流
- 需求远大于供给(供给不足),listing间对于需求的竞争不激烈(listing争抢用户弱),listing之间interference弱,开设listing分流合理
- 需求远小于供给(需求不足),customer之间竞争弱(用户排队争供给不严重),用户侧实验合理
- 供需不平衡,但不存在明显过剩,双边分流(交叉分流),可以基于双边分流debias
- Listing competition: Q00-Q01, 第一行的差异 = 供给争抢用户带来的挤压
- Customer competition: Q00-Q10 = 用户争抢供给带来的挤压
-
-
- 表示TSR naive估计器
- 表示在给定 (customer assignment)和 (listing assignment)条件下的处理效应
-
- 同时开设双边分流
-
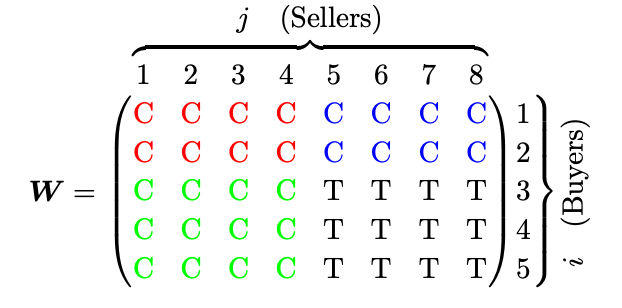
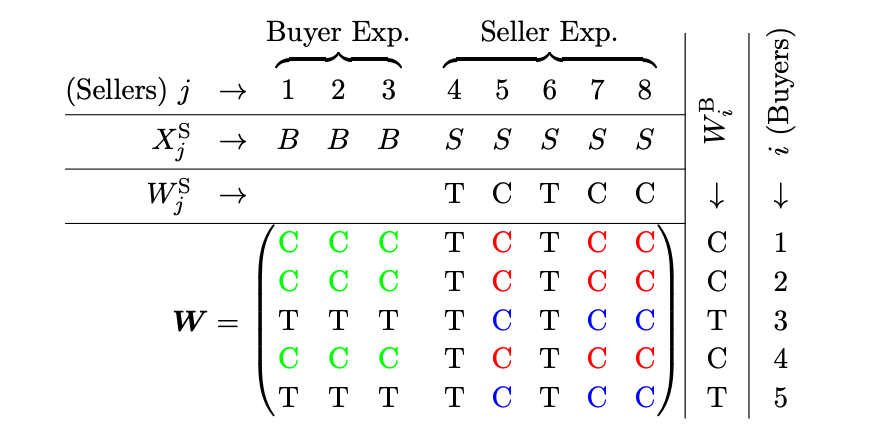
MRD(Multiple Randomization Designs)
- 结果是pair粒度可以观测的,干预可以发生在pair粒度 (例如,特定主播x特定用户生效策略)
- MRD优点
- 没有spillover effect(溢出)时,测量ATE更有效度;
- 有spillover effect(溢出)和interference effect(干扰)时可以度量出来
- 可以在此基础上调整或延展,测量更复杂的溢出或干扰效应。
-
-
- TSR是MRD的一个特例
- 仍然没办法告诉策略推进全的真实effect,但基于local interference假设(每一pair只受同行/同列pair的影响,不受其他影响)可以度量挤压问题;蓝色,绿色与红色的差异可以视为策略的溢出或者挤压效果
- MRD优点
- 结果是pair粒度可以观测的,干预可以发生在pair粒度 (例如,特定主播x特定用户生效策略)
-
类似的思路可以拓展到很多场景下
- 例如一个电商主播扶持 x 用户的实验中
- 主播策略组中流量AB组的差异=扶持策略带来的损失
- 流量空白组中主播AB组的差异=主播行为带来的收益(例如增加投入、供给等)
- 主播空白组中流量AB组的差异=生效用户被挤压的效应
- 例如一个电商主播扶持 x 用户的实验中
-
有时候会叠加双边的隔离
- 例如 快手冷启动: 限制部分冷启动item只能投放在部分流量上,隔离共享样本带来的模型效果溢出
- Reference Zikun Ye, Dennis J. Zhang, Heng Zhang, Renyu Zhang, Xin Chen, Zhiwei Xu (2023), Cold Start to Improve Market Thickness on
Online Advertising Platforms: Data-Driven Algorithms and Field Experiments. Management Science 69(7):3838-3860 -
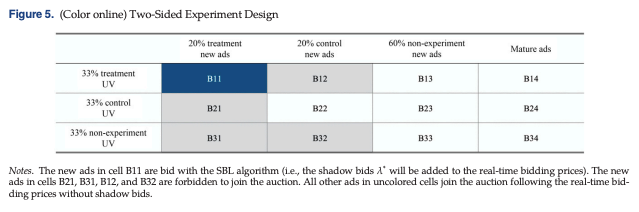
- Reference Zikun Ye, Dennis J. Zhang, Heng Zhang, Renyu Zhang, Xin Chen, Zhiwei Xu (2023), Cold Start to Improve Market Thickness on
- 例如 快手冷启动: 限制部分冷启动item只能投放在部分流量上,隔离共享样本带来的模型效果溢出
Reference
- Patrick Bajari, Brian Burdick, Guido W. Imbens, Lorenzo Masoero, James McQueen, Thomas Richardson, Ido M. Rosen, 2021. Multiple Randomization Designs
-Presentation - Ramesh Johari, Hannah Li, Inessa Liskovich, Gabriel Weintraub,2020. Experimental Design in Two-Sided Platforms: An Analysis of Bias
- Li, et al. Interference, Bias, and Variance in Two-Sided Marketplace Experimentation: Guidance for Platforms
- David Holtz, Ruben Lobel, Inessa Liskovich, Sinan Aral, 2020. Reducing Interference Bias in Online Marketplace Pricing Experiments
Reference
- Xu Jia, Causal Inference Challenges in Industry, A perspective from experiences at LinkedIn; Talk
- Lassen, et al, 2022.Statistical Challenges in Online Controlled Experiments: A Review of A/B Testing Methodology
- Johnson, G. A. (2020, April 20). Inferno: A guide to field experiments in online display advertising.



